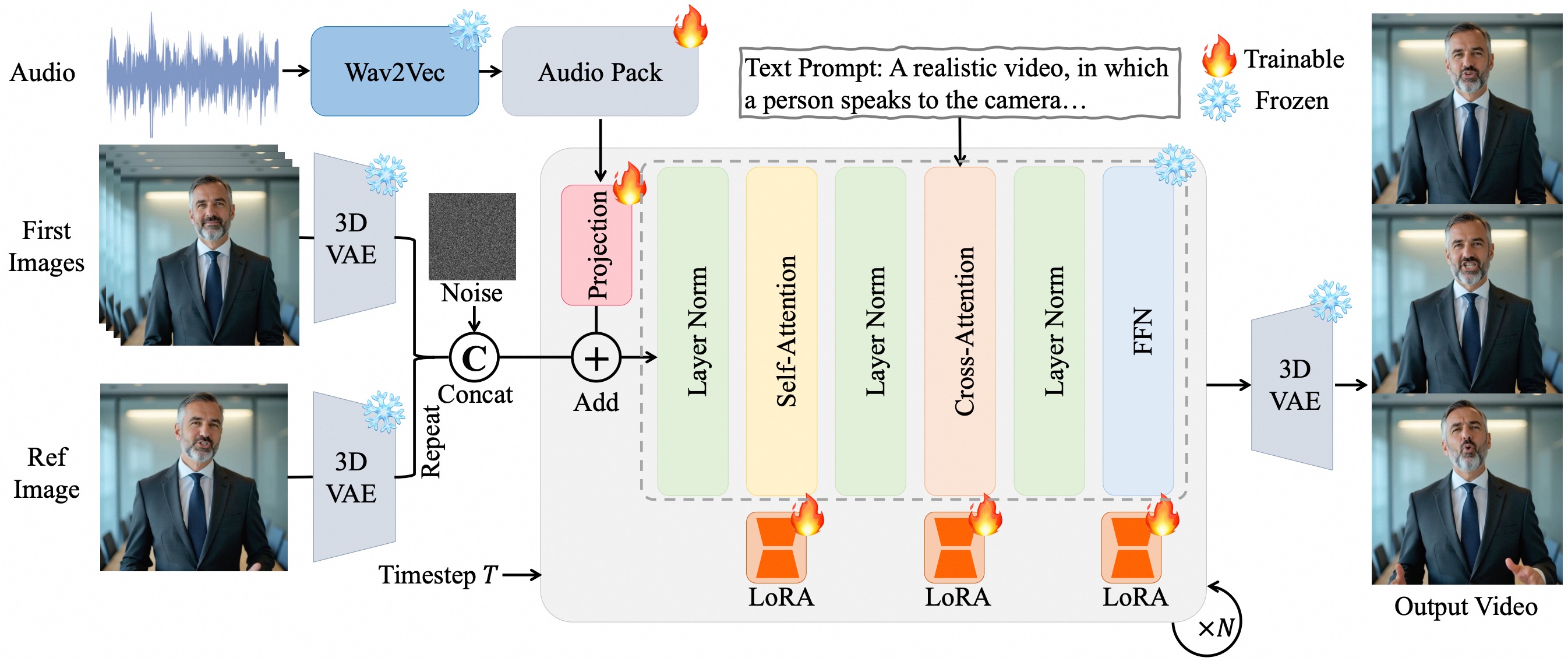
Significant progress has been made in audio-driven human animation, while most existing methods focus mainly on facial movements, limiting their ability to create full-body animations with natural synchronization and fluidity. They also struggle with precise prompt control for fine-grained generation. To tackle these challenges, we introduce OmniAvatar, an innovative audio-driven full-body video generation model that enhances human animation with improved lip-sync accuracy and natural movements. OmniAvatar introduces a pixel-wise multi-hierarchical audio embedding strategy to better capture audio features in the latent space, enhancing lip-syncing across diverse scenes. To preserve the capability for prompt-driven control of foundation models while effectively incorporating audio features, we employ a LoRA-based training approach. Extensive experiments show that OmniAvatar surpasses existing models in both facial and semi-body video generation, offering precise text-based control for creating videos in various domains, such as podcasts, human interactions, dynamic scenes, and singing.